On the Speed of Light, Innovation, and the Future of Parsing
Thursday, April 2nd, 2009(Or, how naïve early-twentieth-century physicists look today,
and how naïve we will look to twenty-second-century developers)
 I’ve always loved the popular story about how early 20th century physicists thought physics was basically “done”. There were just a couple of minor phenomena lacking an explanation, and it was widely believed that they would soon be fully understood. The whole building of physical law would be finished in a matter of years. These “minor phenomena” were the photoelectric effect and the apparently constant speed of light regardless of the observer, as shown by Michelson and Morley in their famous experiment.
I’ve always loved the popular story about how early 20th century physicists thought physics was basically “done”. There were just a couple of minor phenomena lacking an explanation, and it was widely believed that they would soon be fully understood. The whole building of physical law would be finished in a matter of years. These “minor phenomena” were the photoelectric effect and the apparently constant speed of light regardless of the observer, as shown by Michelson and Morley in their famous experiment.
Of course, we now know that explaining these phenomena would give rise to relativity and quantum mechanics. These theories questioned all previous physics, and made us start to actually see the enormous complexity of our universe: it’s not even clear that we’ll ever be able to fully understand it.
In some ways, I feel the computer and software industry is in a similar state. I despair when I see this short-sighted attitude in many developers and computer scientists, despite how primitive our current understanding is. Bill Gates is said to have lured David Cutler into leaving Digital and joining Microsoft to lead the Windows NT effort by asking “Don’t you want to write the last major OS kernel?” Purely as a hiring move, it was obviously a great success. But unfortunately, to many in the industry, current kernels are the last step of the road. Ouch. It’s not only that it’s wrong, but also that this belief impedes original thought and progress.
What we now have are just the first babblings of software – clumsy languages, systems and architectures, poor tools, and primitive theories, which are guaranteed to have an expiry date in the not-very-distant future. It’s sure we won’t be using the current theories and processes in a matter of a few decades.
I recently read an otherwise educated developer remark: “parsing is basically a solved problem”. He probably knew about parsing, maybe even in some depth: recursive descent, LR parsing, lex and yacc and their multiple descendants… But he must have been unable to see beyond that. It’s the only explanation for his affirmation, because I think nothing is further from the truth.
These are the very early days of computing. We have just started exploring the shore of a new continent, and it’s shocking, because many are already proclaiming that it’s over. But the good news is that there is plenty of unconquered territory, most of the settlers have their eyes covered, and they’re not even attempting to grab any of it.
An Itch to Scratch
(Or, a vision, and the twisted path to its completion)
I am somewhat obsessed with visualization and user interfaces: anything that helps you better understand what you are working on, and which helps you create. And for better or worse, all my product ideas are born from an itch I need to scratch myself.
Back in early 2005, I thought it would be awesome to have the following visualization of code while I was editing it:

The goal was to understand at a glance the structure of the code and its control flow. I wanted to see the name of functions and classes highlighted in their definition (the syntax of C-derived languages is notoriously horrible in this regard, hiding the name among a lot of clutter). I also wanted colored regions marking code blocks, visually grouping the code. I wanted to be able to see where everything starts and ends, and see right away the type of each block: red for loops, green for if-blocks, and so on. Statements that break the normal flow of a loop (break, continue) should stand out. All this had to be done in real-time, inside the text editor or IDE, while the code was being edited.
You could call this advanced syntax-highlighting. Actually, what syntax-highlighting usually refers to really isn’t such, because it doesn’t use any syntactic information to color the code. It usually just uses lexical information: the distinction between keywords, operators, numbers, constants, identifiers… Very few tools use any syntactic information for display purposes. And, sadly, this is not done because of a design choice, but because lexical analysis is so much simpler to do.
This feature is the kind of thing that once imagined, you can’t take your mind off. At the moment, I also thought it was completely innovative, as I hadn’t seen it anywhere else. This was one of the features I decided I would include in NGEDIT, the text-editor I was working on. There were many other foundational parts of the editor that still needed work, so I didn’t actually start implementing anything.
![]() Some time after that, my development effort deviated a bit, as I started working in ViEmu, my vi/vim emulator for Visual Studio, Word, Outlook and SQL Server. For ViEmu, I actually adapted the vi/vim emulation core I had written for the editor, so that it could work inside these host apps, and released it as a stand-alone product. I focused exclusively on the ViEmu products for some time, turning them into solid, working products.
Some time after that, my development effort deviated a bit, as I started working in ViEmu, my vi/vim emulator for Visual Studio, Word, Outlook and SQL Server. For ViEmu, I actually adapted the vi/vim emulation core I had written for the editor, so that it could work inside these host apps, and released it as a stand-alone product. I focused exclusively on the ViEmu products for some time, turning them into solid, working products.
During this almost-exclusive stint in ViEmu, I stumbled into a few cases of features similar to the one I had envisioned: Jacob Thurman’s Castalia, which implemented something similar for Delphi, DevExpress’ CodeRush, with a similar version for Visual Studio, and also some scripts for lisp display in emacs. They called it structural highlighting, a name I don’t like much, but which sidesteps the mix-up with syntax-highlighting. Still, none of them did the kind of control-flow-based color-coding I wanted, which is where it becomes really useful information.
Fast forward to early 2007. ViEmu sales were slow for the first few months of the year. I was living off of this, and savings were not huge, so I decided I’d implement another product to try and complement the lousy sales. I had now renamed the text editor to kodumi (a much nicer name if I can say so myself), and it was still work in progress. Actually, it had turned into a major research project that would (and will) still take a long time to complete. If I was going to arrive somewhere shortly, I had to tackle something more manageable.
So I did some digging in the drawer of project and feature ideas. Among the many crazy, undoable concoctions, I came by the “control-flow outlines” idea. On one hand, I still thought it was a cool feature that would really improve the visualization of code. On the other hand, after ViEmu, I had become very familiar with extending the Visual Studio built-in editor (short version: you’ll have to sweat blood to make it do what you want). Together with a few other useful features, it could offer a nice addition to VS. It made sense, and it seemed to be within reach. That would be it.
![]() Inspired on “kana”, the Japanese name of reading and writing systems, I decided to call the product Codekana. And I set out to write it.
Inspired on “kana”, the Japanese name of reading and writing systems, I decided to call the product Codekana. And I set out to write it.
Such a project involves many tasks. There are core technology elements, interaction with the host application, and many more. At the beginning of any project, I like to evaluate the difficulty of each challenge. Adding extra elements to VS’s text editor window was clearly doable: other add-ins were already doing it, and a quick prototype helped me prove it. Filled background regions turned out to be nigh-impossible, due to VS’s internal text-rendering system, but I could draw lines to represent the blocks. This kind of hacking is never simple, or nice, but for an experienced Windows developer, it was a matter of putting in the hours. This was not the hard part.
Even if it is a solved problem to some, it was obvious to me from the first moment what the really hard part was.
It was, of course, the parsing.
On a Whim
(Or how perfectionist thinking can sometimes get you somewhere worthwhile)
I will gloss over the difficulties of parsing C/C++ and C#, which is not an easy job. I will also skip describing the task of implementing a responsive background parser using a multithreaded task-engine. I will even withhold from whining about the difficulties of getting Visual Studio to do what you want.
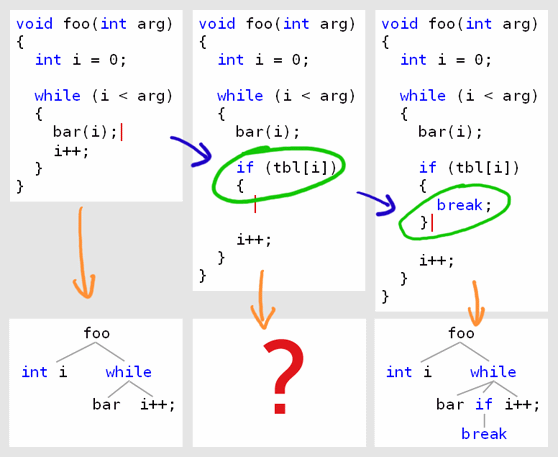
What made everything else seem simplistic in comparison is that, unlike existing tools, I was determined to properly support the free-form editing we do while coding. What do I mean by this? Have a look at the following typical editing session (the cursor is shown in red, and newly inserted text is marked in green):

Sample Editing Session
This session starts from a grammatically correct version of the code, and the source is gradually modified – in this case, just by typing. The end result, on the right, is also grammatically correct. But the intermediate version, when you have typed the new code only partially, is incorrect. In this incorrect version, braces don’t pair properly. There is a new opening brace, which still doesn’t have a matching closing brace. The question here is – what should the Codekana parser do with this version of the code?
Traditional parsing starts from the top and scans linearly. Braces are paired according to a simple logic: a closing brace is understood to close the most recent opening brace that hasn’t been matched. This method works wonderfully in correct source code. But if applied to the intermediate version above, the result will be a surprising. See what pairings this scan will find (in green), and what brace it will leave unmatched (in red):

Naïve linear rescan, starting from the top
Of course, this source code can’t be fully parsed properly, as it’s incorrect. But the parser has detected some pairs and these could be used for display or other purposes. The outline rendering could use the pairs, except that it’s a key problem that the pairs it has found are wrong, they are completely different from the ones found before the typing, and they will be wrong again after the closing brace is typed. A Codekana-like display will get very confused with this intermediate parse.
All traditional tools rescan in this naïve way. Regular compilers of course work this way: they work in “batch mode”, and have far less information than any dynamic parser. If you try to compile the above incorrect code, most compilers will just flag the function body’s opening brace as unmatched. And if there is another function afterwards, the error can be as obscure as “nested function not allowed”, given the compiler will still think we’re inside foo’s body (and, technically, we are).
But even newer interactive-mode parsers, as the ones used by Visual Studio’s own Intellisense, or even JetBrains Resharper’s or DevExpress CodeRush’s parser, will also fall into the same trap. The technique they use for dynamic parsing is “throw everything away and restart”. To avoid extra work, they probably start at the current function or near the editing point, but they don’t go much further than that. In the case above, some of them will even flag as incorrect all code below the editing point. Apart from the erroneous feedback provided, the extra work of re-parsing the rest of the module twice, first when entering the opening brace, and then again when typing the closing one, is nothing to laugh about either.
Of course, they are aware of the problem: an article on Resharper’s blog even complains about C-like languages’ syntax when compared to Visual Basic, where delimiters such as “End If”, “End Loop” and “End Function” allow better parsing with little effort: Of tools and languages.
To alleviate the problem, some of these tools help address this by automatically inserting the matching closing brace, parenthesis or bracket when the user types the opening one. This ameliorates the issue, but it’s not a real fix. Other editing operation sequences can create similar situations, which cannot be fixed with simple hacks.
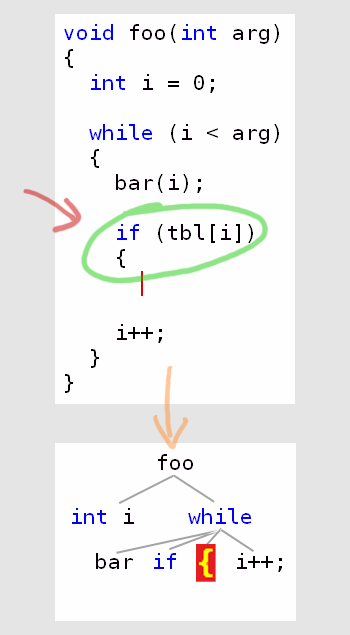
I knew this was what usual techniques afforded, and that this was what current tools were doing. But I had a clear idea of what I wanted to do instead: I wanted Codekana to understand the situation. When re-parsing the code in the case above, the new opening brace shouldn’t pair with the next pre-existing closing brace – it is much more likely that the previous pairings persist, and so the parser should keep them. Here is a screenshot of how I wanted Codekana to treat this case:

Codekana correctly flagging the new, unpaired brace
It’s the new opening brace that is flagged as unpaired, and the previously existing pairings are assumed to remain valid. Codekana also knows that the source is incorrect, but it can apply this heuristic to flag the brace that is most likely the culprit, rather than the one that the naïve linear scan would pinpoint.
The heuristic is the following: assume that it’s the new brace that is unpaired. This is the case most of the time, and applying this logic is the only way to give the correct information to the user. It is also much better than what any other tool out there does.
In the general case, what I wanted was for the parser to use all the information from previous states to understand the editing better, and to better interpret any version of the code. The simplest case of this is what is shown above: flagging the new brace as unpaired, instead of the pre-existing one. But the lead was promising and I could envision more advanced use cases. Code is often incorrect while it is being modified, and the developer still needs all the help he can get. And I’m not only talking about simple non matching-braces: when we ported Commandos 2 from the PC to the PlayStation 2, optimizing memory usage took months, and for extended periods of time, full branches of the one-million-lines-of-C++-code codebase didn’t even compile. Also during regular editing, the code probably spends more time in an incorrect state than in a correct one. Being able to apply refactorings and other complex operations while the code is partially wrong can be very useful.
It’s not only that it works, but that it’s the right thing to do. Enhancing the tools so they can better understand what is happening can only be a net win.
Uncharted Territory
(Or, once you know where you want to get, how you find the way there?)
As with any spec, there are different ways to implement it. Codekana could just try to fully reparse the module and not accept the new text fragments until the whole module parses correctly, flagging these braces as unpaired. This would work, but it’s an ugly hack, it would require a lot of redundant parsing, and wouldn’t work in all cases. But mainly, it’s just not the right solution – it doesn’t scale to higher levels of usefulness.
I did have a look at standard research sources. I knew, because I’m familiar with them, that traditional books on parsing like The Dragon Book or other standard texts on compilers don’t even get close to covering this kind of scenario. What I was trying to do is a form of incremental parsing: reusing the previously existing parse to parse a newer version of the same source.
I had a look at what was available on incremental parsing, and found a few research initiatives, and even mentions of a few products. But it turns out none of them was focused on the kind of problem I was trying to solve. They were either trying to improve the performance of compile times, thus studying incremental analysis between correct versions of the code, or they were trying to study the formal mathematics of incremental parsing, which is a cool thing, but is not very practical. Their approaches would have analyzed the above incorrect source in the naïve and wrong way, the same as current tools do, only they would take much less time to do so. It’s not only important that the parser re-uses existing info, but how it re-uses it.
It was clear I had to design a completely different parsing engine. No existing techniques would be of help. It turned out that by pursuing a clear user-oriented goal, I had deviated from what is considered standard knowledge in parsing theory and practice. It had only taken this to get into uncharted territory. The bad news is that opening new paths can require a lot of effort. The good news is that this is much, much more exciting than being the thousandth implementer of an algorithm from the 70s, and potentially much more rewarding.
So, how could this thing be implemented?
The key to designing and implementing any code is to design what data needs to be stored and how, and the operations that act on it. None of the usual parsing techniques would work for the above case, because none were designed to understand erroneous code.
There is actually a technique called “error productions”, which includes common erroneous code patterns in the grammar of a parser so that the compiler can report errors properly. But this technique does not understand the “ephemeral” nature of code as seen by Codekana in an editing session.
Wait, this was the key! All current techniques deal with quite stable code, while I wanted Codekana to understand how code evolves. Let’s see the parsing structures alongside each version of the code:
Sample editing session with parse trees for the correct versions
With traditional tools, both the first and the last state of the code above have a representation as a “parse tree”, while the state in the middle doesn’t have a parse tree, because it’s incorrect.
The key realization was understanding that I had to extend the traditional parse tree to cover erroneous cases: a branch of the parse tree can contain an unmatched brace, that’s all. This never arises in traditional parsers, because they “experience” the code linearly. However, a dynamic parser experiences the non-linear timeline of editing operations, and thus a new, unpaired brace can appear, and should be inserted, anywhere in the tree. Until another brace comes later to match it, we’ll have to live with an unmatched brace:
Unpaired brace, happily living in the parse tree
If a closing brace is inserted below later, both are detected to match and converted into a proper block.
This treatment extend to other cases: if the closing brace of an existing block is deleted, the opening one will be “downgraded” to unpaired-status, and all the remaining nested or surrounding blocks will remain properly paired. All common cases are understood and properly shown to the user.
The principle also applies to more complex situations: the parsing could understand partially-written declarations, function calls, expressions, or any other structure of the grammar. These partially-complete instances can live happily in the parse tree until they are complete, and can thus be properly treated.
I call this incremental approach “lead-based parsing”, because many of the parsing actions start from actual keywords and operators found in the middle of the code, instead of linearly from any given point. Actually, since incremental parsing has to be done wherever a change happens, the parser always starts “in the middle of the code” in the general case.
Once designed, there are many other intricacies in the implementation, but the actual quantum leap was realizing that a switch of perspective was needed in order to reach the design goal. And this switch took us to a completely new technique in parsing, one of the most studied areas of computing – all in the pursuit of creating a better development experience.
Conclusion
(Or, what does this all mean to you?)
At the end of July 2007, I was able to release Codekana 1.0. It included the incremental parsing system and many other features. It was a small and useful tool, and it will hopefully become much more powerful in the future.
Obviously, Codekana is not “the future of parsing”. It’s just a little tool that can make the life of Visual Studio developers easier. It has gone down a rarely-if-ever-visited path down the world of parsing, and it can offer a much better experience as a result. Actually, it has had to go down that path in order to offer that improved experience.
I do believe that it’s this kind of thinking which will get us to the next generation of computing as a whole. Especially in computers, most things are not even thought about yet, let alone solved and done. In computers, it’s the early 1900s, baby.
Take-aways:
- Never assume that everything is done in any given field.
- When you have a vision, stick to it even if you don’t know how to do it.
- Know what the state-of-the-art is, so that you can use all available tools and you don’t duplicate work.
- Decide the goals around your vision, not around what you can easily do, or you won’t be able to innovate.
- To solve the part not covered by existing techniques, you need to understand the essence of what you are trying to do. But beware: it can take a huge effort to tell what the essence is, and what is just clutter surrounding it.
Innovation is impossible unless you see what is beneath the surface. You can only copy other people’s creations. But as you learn to see the underlying principles, see what you want to achieve, and stick to your vision, innovating becomes unavoidable.
What do I think is the real, actual state-of-the-art in parsing? It’s this: there are lifetimes of research pending to be done in parsing. Turing-award-winning algorithms and techniques to discover. Fortune-making products to be conceived and implemented. This is just in parsing – a small corner of computer science which has been studied to exhaustion. Don’t make me talk about less-explored corners.
Now, please, go, and innovate.

PS: And if you want to check out Codekana, you can start exploring here.
PPS: Thanks to Patrick McKenzie, Eric Sink, Ralf Huvendiek, OJ Reeves, Dennis Gurock, Tobias Gurock, Nick Hebb, Clay Nichols, Andy Brice, Doug Nebeker and Raul Ramos for their early feedback, which helped make it a much better article